
Inference outputs you can enforce
StørmAI consumes deterministic feature vectors from StørmPrep, executes probabilistic inference on GPU, and emits versioned inference objects to StørmDecision and StørmVault. It does not apply policy or enforcement actions.
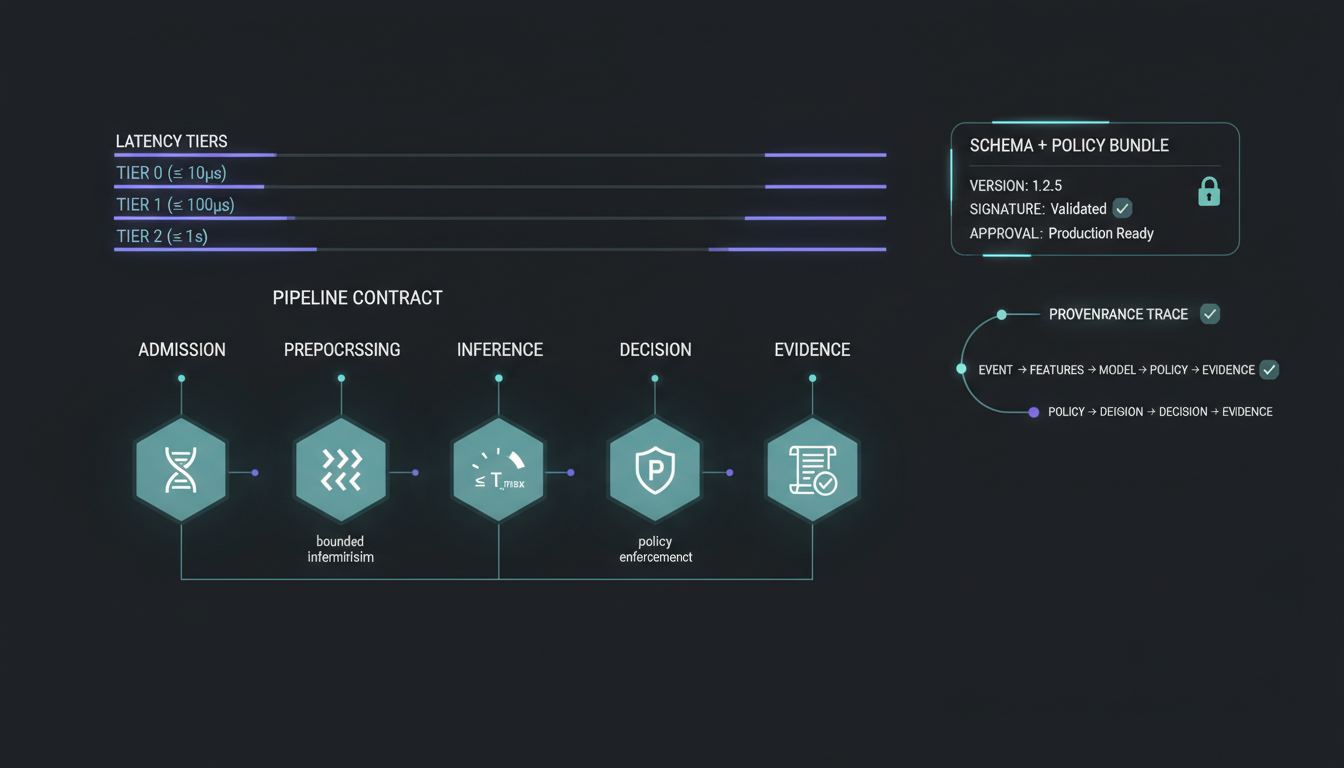
Contract: inputs → outputs
Inputs from StørmPrep, GPU inference processing, and versioned outputs.
Inputs
Deterministic feature vectors and context snapshots from StørmPrep.
Processing
GPU micro-batching with priority lanes and bounded scheduling.
Outputs
Versioned inference objects with provenance to StørmDecision and StørmVault.
How it works
Three steps from governed models to sealed inference outputs.
Load governed model
Signed model packages and routing policies are verified before execution.
Micro-batch inference
GPU micro-batching with priority lanes for bounded latency tiers.
Emit + seal outputs
Inference objects go to StørmDecision and are sealed in StørmVault.
Interfaces
- Inputs: deterministic feature vectors from StørmPrep.
- Outputs: versioned inference objects with confidence and provenance metadata.
- Contracts: model/version governance and reproducibility guarantees.
- Failure semantics: backpressure and bounded degraded mode.
Capabilities
Operational behavior and evidence outputs for the inference plane.
Deterministic features in
StørmAI consumes canonical events and deterministic feature vectors from StørmPrep with schema versions and context snapshots. So what: inference is reproducible for the same inputs and schema version.


Micro-batching and prioritisation
Small, time-bounded batches preserve GPU efficiency while priority lanes and reserved capacity protect enforcement-critical streams. So what: latency remains bounded for critical tiers under load.
Versioned inference outputs
Inference objects include model id, feature schema version, configuration, and confidence bounds, and are sealed in StørmVault. So what: outputs are auditable and attributable.
Model and GPU integrations
StørmAI integrates with signed model registries and GPU inference pools.
- Signed model packages and routing policies verified by StørmTrust.
- GPU runtime and scheduler telemetry for capacity planning.
- Compatibility checks for model, schema, and hardware versions.
So what: model execution stays governed while hardware constraints are visible.
Operational guarantees
- Bounded latency targets with micro-batching and priority lanes.
- Reserved capacity for enforcement-critical streams.
- Deterministic feature dependency on StørmPrep outputs.
- Signed model provenance verified before execution.
